ROC AUC Score
The ROC AUC Score (ROC) [28] computes the Area Under the Receiver Operating Characteristic Curve. By plotting the True Positive Rate (Sensitivity) against the False Positive Rate (1 - Specificity) at various classification thresholds, it quantifies the general ranking capability of a probabilistic classifier.
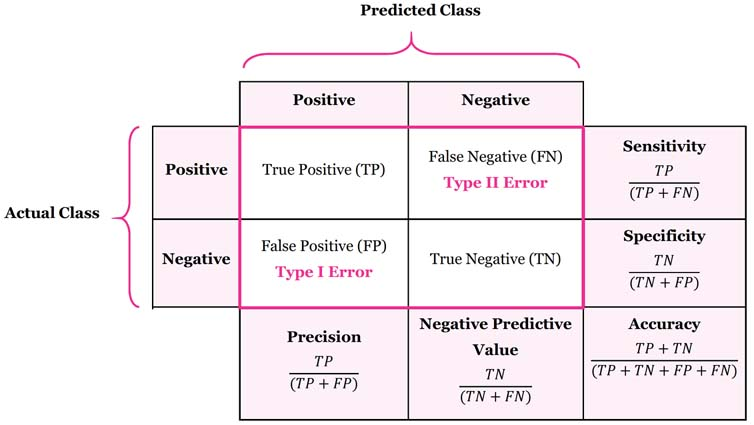
Intuitively, the ROC AUC represents the exact probability that a classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance.
Where \(\tau\) represents the sweeping decision threshold.
Architectural Design: Input Integrity & Safeguards
1. The Probabilistic Input Requirement (y_score)
Unlike accuracy or precision metrics that evaluate discrete label predictions (e.g., [0, 1, 1]), the ROC AUC strictly evaluates continuous confidence scores or uncalibrated decision function outputs (e.g., [0.12, 0.88, 0.94]). Passing discrete class labels degrades the curve into a single step-function coordinate.
2. The Single-Class Exception (Safeguard)
If the test dataset contains only one unique target class (e.g., evaluating a batch of 100% negative samples), the False Positive Rate cannot be swept. permetrics explicitly intercepts this edge case and raises a ValueError rather than returning an uninterpretable NaN.
Multiclass Extension (One-vs-Rest Decomposition)
While classical literature establishes ROC strictly for binary targets, permetrics implements a generalized One-vs-Rest (OvR) scheme for multi-label and multiclass environments:
None: Decomposes the dataset into independent binary targets per class (Class \(c\) vs. Rest) and returns a dictionary mapping each class label to its standalone AUC score.
macro: Calculates the unweighted arithmetic mean of the OvR AUC scores across all classes. This treats minority and majority classes with equal weight.
weighted: Calculates the OvR AUC scores and computes their mean weighted by the actual class prevalence in the ground truth.
Benchmark Interpretation Scale
AUC Score |
Discriminative Capacity |
|---|---|
0.50 |
No Discrimination (Random Guess) |
0.51 - 0.70 |
Poor Discrimination |
0.71 - 0.80 |
Acceptable Discrimination |
0.81 - 0.90 |
Excellent Discrimination |
> 0.90 |
Outstanding Discrimination |
Properties
Best possible score:
1.0(Perfect ranking; every positive instance is scored higher than any negative instance).Baseline score:
0.5(Equivalent to random ranking).Range:
[0.0, 1.0](Values below 0.5 indicate systematic label inversion).References: Scikit-Learn roc_auc_score
Example Usage
from permetrics.classification import ClassificationMetric
# ==============================================================================
# SCENARIO 1: Binary Classification (Passing Probability Scores)
# y_pred expects continuous probability scores belonging to the Positive Class
# ==============================================================================
print("--- 1. BINARY CLASSIFICATION EXAMPLES ---")
y_true_bin = [0, 0, 1, 1]
y_score_bin = [0.1, 0.4, 0.35, 0.8]
cm_bin = ClassificationMetric(y_true_bin, y_score_bin)
print(f"Binary ROC AUC Score : {cm_bin.ROC()}")
# Passing a 2D matrix of probabilities (e.g., direct output from .predict_proba())
y_score_2d = [[0.9, 0.1], [0.6, 0.4], [0.65, 0.35], [0.2, 0.8]]
cm_2d = ClassificationMetric(y_true_bin, y_score_2d)
print(f"Binary ROC (2D Input): {cm_2d.ROC()}")
# ==============================================================================
# SCENARIO 2: Multiclass Classification (One-vs-Rest)
# y_pred expects a 2D array of shape (n_samples, n_classes)
# ==============================================================================
print("\n--- 2. MULTICLASS OVR EXAMPLES ---")
y_true_multi = [0, 1, 2, 0, 1, 2]
y_score_multi = [
[0.7, 0.2, 0.1], [0.1, 0.8, 0.1], [0.2, 0.2, 0.6],
[0.8, 0.1, 0.1], [0.3, 0.6, 0.1], [0.1, 0.1, 0.8]
]
cm_multi = ClassificationMetric(y_true_multi, y_score_multi)
print(f"average=None (Class dict) : {cm_multi.ROC(average=None)}")
print(f"average='macro' : {cm_multi.ROC(average='macro')}")
print(f"average='weighted' : {cm_multi.ROC(average='weighted')}")