LS - Lift Score
The Lift Score (LS) measures the ratio of the model’s precision to the prior probability of the target class (the baseline prevalence). It quantifies the effectiveness of a classification model compared to a random selection baseline.
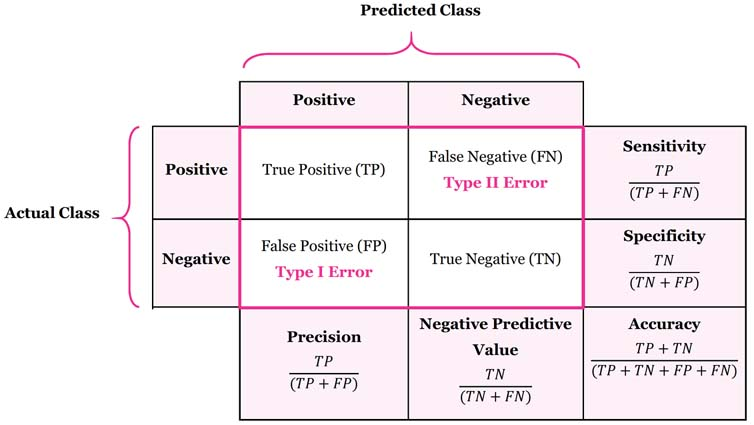
Intuitively, Lift answers the vital engineering question: “How many times better is our predictive model at catching target instances compared to just selecting samples randomly without any model?”
Where:
\(TP\), \(FP\), and \(FN\) are True Positives, False Positives, and False Negatives, respectively.
\(N\) is the total number of evaluated samples.
\(\frac{TP + FN}{N}\) represents the prior base rate (prevalence) of the class in the dataset.
Averaging Strategies (Multiclass / Multilabel)
When handling more than two classes, the Lift Score is calculated per individual class and aggregated via the average parameter:
None: Returns an array/dictionary of independent Lift scores for each individual target class.
macro: Calculates the unweighted arithmetic mean of the Lift scores across all classes.
micro: Calculates globally across the aggregate matrix. (Mathematical Note: In standard single-label multiclass problems where Micro Precision equals Micro Accuracy and Base Rate equals 1, Micro Lift strictly evaluates to ``1.0``).
weighted: Calculates the class-specific Lift scores and computes their mean weighted by the true class support size.
Properties
Best possible score: Approaches \(\frac{N}{TP+FN}\) (The inverse of the class prevalence. For extremely rare classes, the maximum Lift can be very large).
Baseline score:
1.0(Equivalent to random guessing).Worst possible score:
0.0Range:
[0.0, +inf)Developer Insight (Marketing & Fraud Target Selection): In Direct Marketing pipelines where response rates are 1% (Base Rate = 0.01), sending promotions to everyone wastes budget. If your model achieves a Lift Score of
5.0on the top decile, you can target only the predicted positive users and capture 5x more conversions per dollar spent than a random broadcast.References: * Mlxtend Framework
Example Usage
from permetrics.classification import ClassificationMetric
# ==============================================================================
# SCENARIO 1: Binary Classification
# The default 'binary' mode requires a specific positive class (pos_label)
# ==============================================================================
print("--- 1. BINARY CLASSIFICATION EXAMPLES ---")
y_true_bin = [0, 1, 0, 0, 1, 0]
y_pred_bin = [0, 1, 0, 0, 0, 1]
cm_bin = ClassificationMetric(y_true_bin, y_pred_bin)
# 1. Default configuration: average="binary", pos_label=1
ls_bin_default = cm_bin.LS()
print(f"Default (average='binary', pos_label=1): {ls_bin_default}")
# 2. Change pos_label to 0 (evaluates Lift relative to target class 0)
ls_bin_pos0 = cm_bin.LS(average="binary", pos_label=0)
print(f"Binary with pos_label=0 : {ls_bin_pos0}")
# 3. When average=None, it returns independent Lift scores per class
ls_bin_none = cm_bin.LS(average=None)
print(f"Binary with average=None : {ls_bin_none}")
# ==============================================================================
# SCENARIO 2: Multiclass Classification with Integer Labels
# ==============================================================================
print("\n--- 2. MULTICLASS (INTEGER LABELS) EXAMPLES ---")
y_true_multi_int = [0, 1, 2, 0, 1, 2, 0, 2]
y_pred_multi_int = [0, 2, 1, 0, 1, 1, 0, 2]
cm_multi_int = ClassificationMetric(y_true_multi_int, y_pred_multi_int)
print(f"average=None : {cm_multi_int.LS(average=None)}")
print(f"average='macro' : {cm_multi_int.LS(average='macro')}")
print(f"average='micro' : {cm_multi_int.LS(average='micro')}")
print(f"average='weighted' : {cm_multi_int.LS(average='weighted')}")
# Filter specific classes
print(f"Filter classes [1, 2] (average=None) : {cm_multi_int.LS(labels=[1, 2], average=None)}")
print(f"Filter classes [1, 2] (average='macro') : {cm_multi_int.LS(labels=[1, 2], average='macro')}")
print(f"Filter classes [1, 2] (average='micro') : {cm_multi_int.LS(labels=[1, 2], average='micro')}")
print(f"Filter classes [1, 2] (average='weighted'): {cm_multi_int.LS(labels=[1, 2], average='weighted')}")
# ==============================================================================
# SCENARIO 3: Multiclass Classification with Categorical/String Labels
# ==============================================================================
print("\n--- 3. MULTICLASS (CATEGORICAL/STRING LABELS) EXAMPLES ---")
y_true_str = ["cat", "ant", "cat", "cat", "ant", "bird", "bird", "bird"]
y_pred_str = ["ant", "ant", "cat", "cat", "ant", "cat", "bird", "ant"]
cm_str = ClassificationMetric(y_true_str, y_pred_str)
print(f"average=None (Class dict) : {cm_str.LS(average=None)}")
print(f"average='macro' : {cm_str.LS(average='macro')}")
print(f"average='micro' : {cm_str.LS(average='micro')}")
print(f"average='weighted' : {cm_str.LS(average='weighted')}")
# Filter string labels
print(f"Filter 'cat' & 'bird' (average=None) : {cm_str.LS(labels=['cat', 'bird'], average=None)}")
print(f"Filter 'cat' & 'bird' (average='macro') : {cm_str.LS(labels=['cat', 'bird'], average='macro')}")
print(f"Filter 'cat' & 'bird' (average='micro') : {cm_str.LS(labels=['cat', 'bird'], average='micro')}")
print(f"Filter 'cat' & 'bird' (average='weighted'): {cm_str.LS(labels=['cat', 'bird'], average='weighted')}")