KLDL - Kullback-Leibler Divergence Loss
The Kullback-Leibler Divergence Loss (KLDL) [30] (widely celebrated as Relative Entropy) measures how one reference probability distribution \(P\) diverges from a second candidate probability distribution \(Q\).
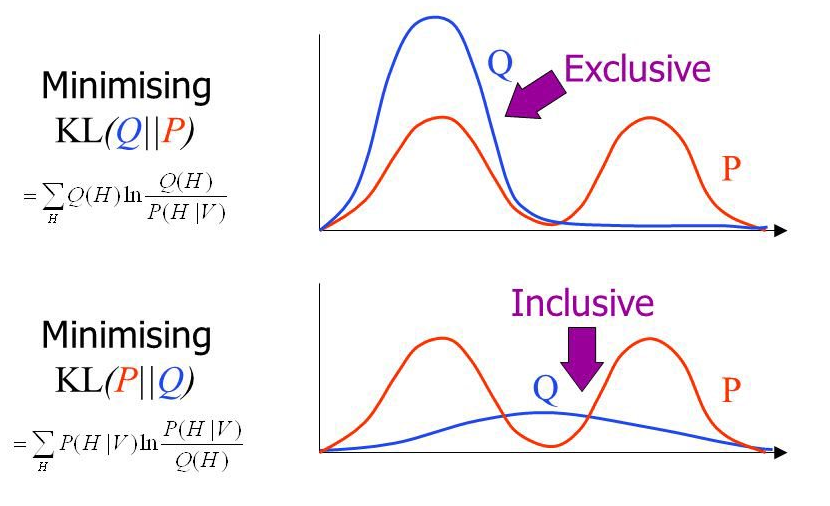
In machine learning classification, it quantifies the exact information lost when the predicted probability distribution \(\hat{Y}\) is used to approximate the ground truth target distribution \(Y\).
Architectural Design: Polymorphic Target Ingestion
Unlike standard implementations restricted to discrete integer targets, permetrics dynamically parses the semantic structure of the supplied ground truth array \(Y\):
Hard Target Binarization (Standard Classification): If discrete class indices are passed (e.g.,
[0, 2, 1]), the engine dynamically projects them into internal One-Hot distributions. (Note: On strict One-Hot targets where base Entropy is zero, KLDL simplifies mathematically into Cross-Entropy / Log Loss).Soft Target Preservation (Knowledge Distillation): If continuous target probability matrices are passed (e.g.,
[[0.8, 0.2], [0.1, 0.9]]generated by a Teacher LLM), the engine preserves target entropy, computing the true asymmetric relative divergence.
Numerical Stability Strategy
To bypass the classic floating-point hazard where zero-probability ground truths trigger undefined operations (\(0 \times -\infty = \text{NaN}\)), the implementation applies a conditional logarithmic mask. Wherever target class probability \(y_{ik} = 0\), the log-ratio is evaluated strictly as \(\log(1.0) = 0\), guaranteeing zero numerical pollution without distorting the reference target distribution with arbitrary Epsilon clipping.
Properties
Best possible score:
0.0(Lower value is better; indicates two statistically indistinguishable distributions).Worst possible score: Unbounded (\(+\infty\)).
Range:
[0.0, +\infty)Optimizer Note: KLDL is a Loss metric. Hyperparameter search engines must be configured to minimize.
Example Usage
from permetrics.classification import ClassificationMetric
# ==============================================================================
# SCENARIO 1: Standard Discrete Targets (Hard Labels)
# ==============================================================================
print("--- 1. HARD LABEL DIVERGENCE ---")
y_true_hard = [0, 1, 1]
y_pred_prob = [[0.9, 0.1], [0.2, 0.8], [0.1, 0.9]]
cm_hard = ClassificationMetric(y_true_hard, y_pred_prob)
print(f"Hard KLDL (Identical to Log Loss): {cm_hard.KLDL()}")
# ==============================================================================
# SCENARIO 2: Knowledge Distillation (Soft Targets)
# y_true is a continuous probability distribution from a Teacher Model
# ==============================================================================
print("\n--- 2. SOFT LABEL DIVERGENCE (DISTILLATION) ---")
y_true_soft = [[0.85, 0.15], [0.10, 0.90], [0.25, 0.75]]
y_pred_student = [[0.80, 0.20], [0.15, 0.85], [0.40, 0.60]]
cm_soft = ClassificationMetric(y_true_soft, y_pred_student)
print(f"Teacher-Student KLDL : {cm_soft.KLDL()}")