CKS - Cohen’s Kappa Score
Cohen’s Kappa Score (CKS) [24] is a robust statistical measure of inter-rater agreement for categorical items. In classification benchmarking, it measures the level of agreement between the Predicted Labels and the True Ground Truth, while strictly compensating for the agreement that could happen purely by chance.
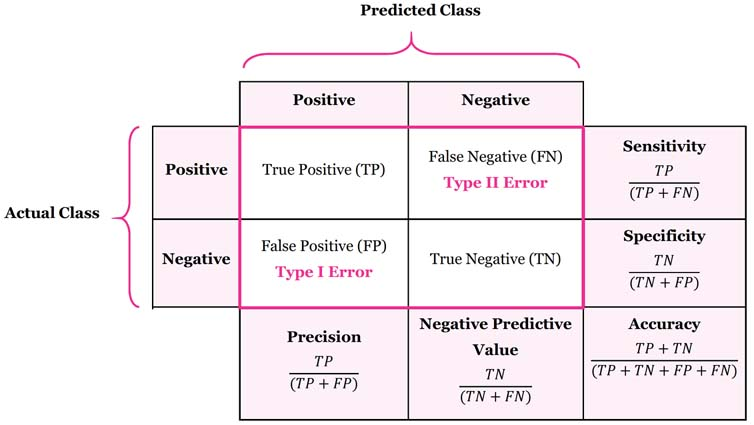
Where:
\(p_o\) is the relative observed agreement among raters (identical to accuracy: \(\frac{TP + TN}{N}\)).
\(p_e\) is the hypothetical probability of chance agreement, calculated using the marginal probabilities of each class.
Engineering Insight: The “Lucky Guess” Filter
Accuracy completely fails on imbalanced datasets because it treats lucky guesses as skill.
- Imagine an automated fraud detection engine evaluating 100 transactions (95 legitimate, 5 fraudulent). A broken model simply outputs “legitimate” 100% of the time:
Accuracy (\(p_o\)):
0.95Expected Chance Agreement (\(p_e\)): The ground truth has 95% legitimate. The model predicts 100% legitimate. The probability of both randomly matching “legitimate” is \(0.95 \times 1.0 = 0.95\).
Cohen’s Kappa: \(\frac{0.95 - 0.95}{1 - 0.95} = \mathbf{0.0}\)
While Accuracy awards the broken model a 95%, Cohen’s Kappa returns a brutal 0.0, mathematically proving that the model possesses zero predictive intelligence beyond baseline chance.
Architectural Design: One-vs-Rest Decomposition
Standard statistical literature defines multiclass Kappa over a single global \(K \times K\) matrix. permetrics extends this paradigm by decomposing multiclass problems into independent One-vs-Rest (OvR) \(2 \times 2\) confusion matrices per class, calculating class-specific Kappa scores, and aggregating them via the average parameter:
None: Returns a dictionary/array of independent chance-corrected agreement scores for each target class.
macro: Computes the unweighted mean of the One-vs-Rest Kappa scores. This highlights models that maintain genuine predictive skill across rare minority classes.
micro: Calculates globally across the aggregate matrix.
weighted: Computes the mean of the OvR Kappa scores weighted by true class support.
Benchmark Interpretation Scale
According to the landmark guidelines by Landis & Koch (1977), Kappa values are categorized as follows:
Kappa Score |
Strength of Agreement |
|---|---|
< 0.00 |
Poor (Systematic Disagreement) |
0.00 - 0.20 |
Slight Agreement |
0.21 - 0.40 |
Fair Agreement |
0.41 - 0.60 |
Moderate Agreement |
0.61 - 0.80 |
Substantial Agreement |
0.81 - 1.00 |
Almost Perfect Agreement |
Properties
Best possible score:
1.0(Perfect agreement between predictions and reality).Baseline score:
0.0(Agreement is exactly what would be expected by random chance).Worst possible score:
-1.0(Systematic inverse agreement; predictions are systematically wronger than random chance).Range:
[-1.0, 1.0]
Example Usage
from permetrics.classification import ClassificationMetric
# ==============================================================================
# SCENARIO 1: Binary Classification
# The default 'binary' mode requires a specific positive class (pos_label)
# ==============================================================================
print("--- 1. BINARY CLASSIFICATION EXAMPLES ---")
y_true_bin = [0, 1, 0, 0, 1, 0]
y_pred_bin = [0, 1, 0, 0, 0, 1]
cm_bin = ClassificationMetric(y_true_bin, y_pred_bin)
# 1. Default configuration: average="binary", pos_label=1
cks_bin_default = cm_bin.CKS()
print(f"Default (average='binary', pos_label=1): {cks_bin_default}")
# 2. Change pos_label to 0
cks_bin_pos0 = cm_bin.CKS(average="binary", pos_label=0)
print(f"Binary with pos_label=0 : {cks_bin_pos0}")
# 3. Independent chance-adjusted scores per class
cks_bin_none = cm_bin.CKS(average=None)
print(f"Binary with average=None : {cks_bin_none}")
# ==============================================================================
# SCENARIO 2: Multiclass Classification with Integer Labels
# ==============================================================================
print("\n--- 2. MULTICLASS (INTEGER LABELS) EXAMPLES ---")
y_true_multi_int = [0, 1, 2, 0, 1, 2, 0, 2]
y_pred_multi_int = [0, 2, 1, 0, 1, 1, 0, 2]
cm_multi_int = ClassificationMetric(y_true_multi_int, y_pred_multi_int)
print(f"average=None : {cm_multi_int.CKS(average=None)}")
print(f"average='macro' : {cm_multi_int.CKS(average='macro')}")
print(f"average='micro' : {cm_multi_int.CKS(average='micro')}")
print(f"average='weighted' : {cm_multi_int.CKS(average='weighted')}")
# Filter specific classes
print(f"Filter classes [1, 2] (average=None) : {cm_multi_int.CKS(labels=[1, 2], average=None)}")
print(f"Filter classes [1, 2] (average='macro') : {cm_multi_int.CKS(labels=[1, 2], average='macro')}")
print(f"Filter classes [1, 2] (average='micro') : {cm_multi_int.CKS(labels=[1, 2], average='micro')}")
print(f"Filter classes [1, 2] (average='weighted'): {cm_multi_int.CKS(labels=[1, 2], average='weighted')}")
# ==============================================================================
# SCENARIO 3: Multiclass Classification with Categorical/String Labels
# ==============================================================================
print("\n--- 3. MULTICLASS (CATEGORICAL/STRING LABELS) EXAMPLES ---")
y_true_str = ["cat", "ant", "cat", "cat", "ant", "bird", "bird", "bird"]
y_pred_str = ["ant", "ant", "cat", "cat", "ant", "cat", "bird", "ant"]
cm_str = ClassificationMetric(y_true_str, y_pred_str)
print(f"average=None (Class dict) : {cm_str.CKS(average=None)}")
print(f"average='macro' : {cm_str.CKS(average='macro')}")
print(f"average='micro' : {cm_str.CKS(average='micro')}")
print(f"average='weighted' : {cm_str.CKS(average='weighted')}")