F1S - F1 Score
The F1 Score (F1S) is the harmonic mean of Precision and Recall. It synthesizes both metrics into a single single-digit benchmark, making it the premier evaluation standard for imbalanced classification problems.
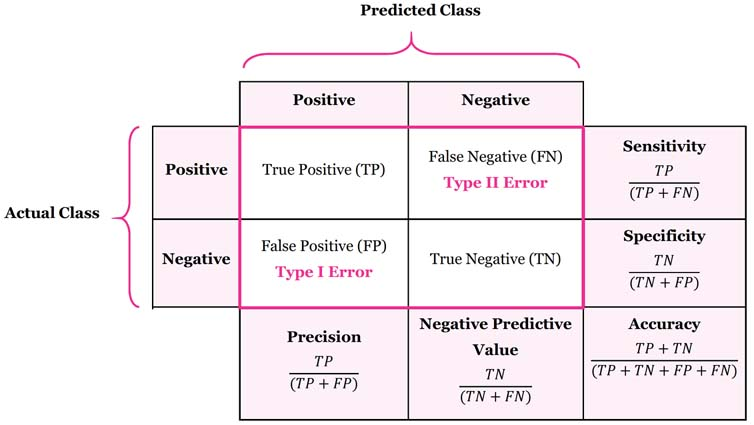
Unlike the arithmetic mean, which allows a high score in one metric to mask a catastrophic failure in the other, the harmonic mean disproportionately penalizes extreme disparities. To achieve a high F1 score, a classifier must demonstrate strong performance in both Precision and Recall simultaneously.
Averaging Strategies (Multiclass / Multilabel)
When handling more than two classes, the F1 score is computed per class and then aggregated using one of the following average parameters:
None: Returns an array/dictionary of independent F1 scores for each individual class.
macro: Calculates the unweighted arithmetic mean of the class F1 scores. It treats a rare class with 10 samples with the exact same importance as a majority class with 10,000 samples.
- micro: Calculates globally by aggregating the total true positives, false negatives, and false positives across all classes.
(Mathematical Easter Egg: In standard single-label multiclass classification, Micro-F1 is mathematically identical to the Overall Accuracy).
weighted: Calculates the F1 score for each class and computes their average weighted by class support. This solves the distortion caused by macro-averaging on highly imbalanced datasets.
Properties
Best possible score:
1.0(Indicates perfect Precision and perfect Recall).Worst possible score:
0.0(Occurs if either Precision or Recall drops to zero).Range:
[0.0, 1.0]Engineering Insight (The Imbalanced Data Benchmark): In scenarios like Ad Click-Through Rate (CTR) prediction where clicks represent 0.1% of the data, a naive model predicting “No Click” 100% of the time will achieve an Accuracy of
0.999. F1 immediately exposes this useless model by returning an F1 score of0.0.- References: * Scikit-Learn F1-Score Documentation,
Example Usage
from permetrics.classification import ClassificationMetric
# ==============================================================================
# SCENARIO 1: Binary Classification
# The default 'binary' mode requires a specific positive class (pos_label)
# ==============================================================================
print("--- 1. BINARY CLASSIFICATION EXAMPLES ---")
y_true_bin = [0, 1, 0, 0, 1, 0]
y_pred_bin = [0, 1, 0, 0, 0, 1]
cm_bin = ClassificationMetric(y_true_bin, y_pred_bin)
# 1. Default configuration: average="binary", pos_label=1
f1_bin_default = cm_bin.F1S()
print(f"Default (average='binary', pos_label=1): {f1_bin_default}")
# 2. Change pos_label to 0 (treats 0 as the target positive class)
f1_bin_pos0 = cm_bin.F1S(average="binary", pos_label=0)
print(f"Binary with pos_label=0 : {f1_bin_pos0}")
# 3. When average=None, it returns independent scores for each class found
f1_bin_none = cm_bin.F1S(average=None)
print(f"Binary with average=None : {f1_bin_none}")
# ==============================================================================
# SCENARIO 2: Multiclass Classification with Integer Labels
# ==============================================================================
print("\n--- 2. MULTICLASS (INTEGER LABELS) EXAMPLES ---")
y_true_multi_int = [0, 1, 2, 0, 1, 2, 0, 2]
y_pred_multi_int = [0, 2, 1, 0, 1, 1, 0, 2]
cm_multi_int = ClassificationMetric(y_true_multi_int, y_pred_multi_int)
print(f"average=None : {cm_multi_int.F1S(average=None)}")
print(f"average='macro' : {cm_multi_int.F1S(average='macro')}")
print(f"average='micro' : {cm_multi_int.F1S(average='micro')}")
print(f"average='weighted' : {cm_multi_int.F1S(average='weighted')}")
# Using the `labels` parameter to filter specific classes
print(f"Filter classes [1, 2] (average=None) : {cm_multi_int.F1S(labels=[1, 2], average=None)}")
print(f"Filter classes [1, 2] (average='macro') : {cm_multi_int.F1S(labels=[1, 2], average='macro')}")
print(f"Filter classes [1, 2] (average='micro') : {cm_multi_int.F1S(labels=[1, 2], average='micro')}")
print(f"Filter classes [1, 2] (average='weighted'): {cm_multi_int.F1S(labels=[1, 2], average='weighted')}")
# ==============================================================================
# SCENARIO 3: Multiclass Classification with Categorical/String Labels
# ==============================================================================
print("\n--- 3. MULTICLASS (CATEGORICAL/STRING LABELS) EXAMPLES ---")
y_true_str = ["cat", "ant", "cat", "cat", "ant", "bird", "bird", "bird"]
y_pred_str = ["ant", "ant", "cat", "cat", "ant", "cat", "bird", "ant"]
cm_str = ClassificationMetric(y_true_str, y_pred_str)
print(f"average=None (Class dict) : {cm_str.F1S(average=None)}")
print(f"average='macro' : {cm_str.F1S(average='macro')}")
print(f"average='micro' : {cm_str.F1S(average='micro')}")
print(f"average='weighted' : {cm_str.F1S(average='weighted')}")
# Filter string labels: Focus calculation entirely on 'cat' and 'bird'
print(f"Filter 'cat' & 'bird' (average=None) : {cm_str.F1S(labels=['cat', 'bird'], average=None)}")
print(f"Filter 'cat' & 'bird' (average='macro') : {cm_str.F1S(labels=['cat', 'bird'], average='macro')}")
print(f"Filter 'cat' & 'bird' (average='micro') : {cm_str.F1S(labels=['cat', 'bird'], average='micro')}")
print(f"Filter 'cat' & 'bird' (average='weighted'): {cm_str.F1S(labels=['cat', 'bird'], average='weighted')}")