AS - Accuracy Score
The Accuracy Score (AS) computes either the fraction (floating point) or the absolute count (integer) of correctly classified samples.
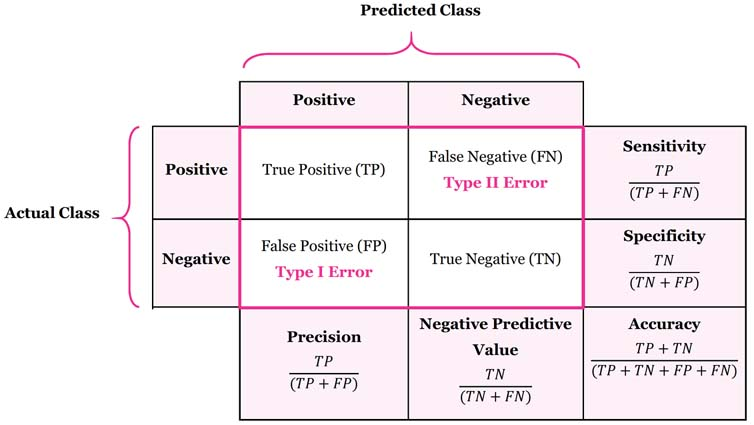
In multiclass and multi-label classification tasks, the Accuracy Score strictly enforces Subset Accuracy (Exact Match): the entire set of predicted labels for a given sample must strictly match the true set of labels to be counted as correct.
Where:
\(I(\cdot)\) is the indicator function, returning
1if the prediction matches the ground truth strictly (\(y_i = \hat{y}_i\)), and0otherwise.\(N\) is the total number of evaluated samples.
Architectural Parameters
The normalize Toggle (Dynamic Return Type)
normalize=True(Default): Returns the proportion of correctly classified samples. The output is afloatstrictly bounded in the range[0.0, 1.0].normalize=False: Returns the raw tally of correctly classified samples. The output is anintstrictly bounded in the range[0, N].
2. The sample_weight Parameter Allows assigning non-uniform mathematical importance to individual observations. When weighted, the score computes:
Engineering Insight: The Accuracy Paradox
While Accuracy is the most universally recognized machine learning metric, developers must treat it with extreme caution on Imbalanced Datasets.
Consider a server network monitoring log containing 9,990 normal packets and 10 malicious DDoS packets. A completely broken, hardcoded model outputs “normal” for 100% of the traffic. * It scores \(\frac{9990}{10000} = \mathbf{0.999}\) (99.9% Accuracy).
The metric dangerously validates a model that possesses zero capability to detect cyberattacks. When auditing imbalanced pipelines, developers should always cross-verify AS against Matthews Correlation Coefficient (MCC) or Balanced Accuracy.
Properties
Best possible score:
1.0(if normalize=True) orN(if normalize=False).Worst possible score:
0.0Range:
[0.0, 1.0]or[0, N]References: Scikit-Learn Accuracy Score Documentation
Example Usage
from permetrics.classification import ClassificationMetric
# ==============================================================================
# SCENARIO 1: Standard Accuracy (Testing the `normalize` parameter)
# y_true and y_pred have 6 samples; exactly 4 are predicted correctly.
# ==============================================================================
print("--- 1. STANDARD ACCURACY EXAMPLES ---")
y_true = [0, 2, 1, 3, 0, 2]
y_pred = [0, 1, 2, 3, 0, 2] # Errors at index 1 and 2
cm = ClassificationMetric(y_true, y_pred)
# 1. Default (normalize=True) -> Returns float: 4 / 6 = 0.6666...
print(f"AS proportion (normalize=True) : {cm.AS()}")
# 2. Raw Tally (normalize=False) -> Returns int: exactly 4 correct
print(f"AS raw count (normalize=False): {cm.AS(normalize=False)}")
# ==============================================================================
# SCENARIO 2: Weighted Accuracy
# Suppose the error at index 1 was a critical VIP transaction (weight = 10)
# ==============================================================================
print("\n--- 2. WEIGHTED ACCURACY EXAMPLES ---")
sample_weights = [1.0, 10.0, 1.0, 1.0, 1.0, 1.0] # Sum of weights = 15.0
cm_weighted = ClassificationMetric(y_true, y_pred)
# Correct samples are at index: 0 (w=1), 3 (w=1), 4 (w=1), 5 (w=1) -> Sum = 4.0
# Weighted Score = 4.0 / 15.0 = 0.2666...
print(f"Weighted AS (normalize=True) : {cm_weighted.AS(sample_weight=sample_weights)}")