HML - Hamming Loss
The Hamming Loss (HML) calculates the fraction of labels that are incorrectly predicted. Unlike accuracy scores that reward correct predictions, Hamming Loss strictly quantifies the error rate across the classification model.
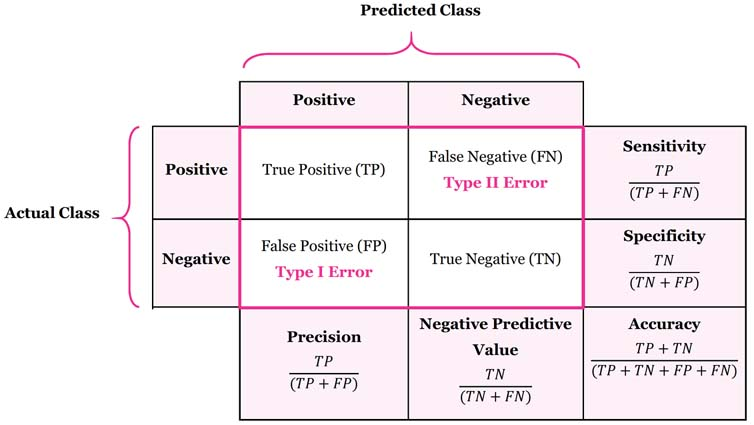
In standard single-label multiclass classification, the Hamming Loss corresponds directly to the Zero-One Loss (the exact complement of Accuracy). It answers the fundamental engineering question: “What exact proportion of the predicted class labels are wrong?”
Where:
\(I(\cdot)\) is the indicator function, which equals
1if the prediction is incorrect (\(y_i \neq \hat{y}_i\)) and0if correct.\(N\) is the total number of evaluated samples.
Averaging Strategies
None: Returns a dictionary/array containing the independent Hamming Loss rates for each target class.
macro: Calculates the unweighted mean of the Hamming Loss across all classes.
micro: Calculates globally across the entire matrix. (Mathematical Note: In single-label multiclass problems, Micro Hamming Loss strictly equals :math:`1 - text{Micro Accuracy}`).
weighted: Calculates the class-specific loss rates and computes their mean weighted by the true class support size.
Beyond Scikit-Learn: Scikit-Learn defines Hamming Loss strictly as a global, unweighted metric.
permetricsdeliberately extends this concept to support macro and weighted averaging.
On heavily imbalanced datasets, global loss can be deceptively low. By evaluating HML(average='macro'), the engine isolates the independent loss rate for each individual class \(\left(\frac{FP_c + FN_c}{N}\right)\) and computes their unweighted arithmetic mean. This immediately exposes flawed models that achieve a low global error simply by sacrificing rare minority classes.
Properties
Best possible score:
0.0(Lower value is better, indicating zero misclassifications).Worst possible score:
1.0(100% of the predictions are completely incorrect).Range:
[0.0, 1.0]Optimizer Warning: Always remember that HML is a Loss function. When configuring hyperparameter tuning grids (like GridSearchCV), ensure your optimization engine is explicitly set to minimize this metric.
References: * Scikit-Learn Hamming Loss Documentation
Example Usage
from permetrics.classification import ClassificationMetric
# ==============================================================================
# SCENARIO 1: Binary Classification
# The default 'binary' mode requires a specific positive class (pos_label)
# ==============================================================================
print("--- 1. BINARY CLASSIFICATION EXAMPLES ---")
y_true_bin = [0, 1, 0, 0, 1, 0]
y_pred_bin = [0, 1, 0, 0, 0, 1]
cm_bin = ClassificationMetric(y_true_bin, y_pred_bin)
# 1. Default configuration: average="binary", pos_label=1
hl_bin_default = cm_bin.HML()
print(f"Default (average='binary', pos_label=1): {hl_bin_default}")
# 2. Change pos_label to 0 (evaluates loss relative to target class 0)
hl_bin_pos0 = cm_bin.HML(average="binary", pos_label=0)
print(f"Binary with pos_label=0 : {hl_bin_pos0}")
# 3. When average=None, it returns independent loss rates per class
hl_bin_none = cm_bin.HML(average=None)
print(f"Binary with average=None : {hl_bin_none}")
# ==============================================================================
# SCENARIO 2: Multiclass Classification with Integer Labels
# ==============================================================================
print("\n--- 2. MULTICLASS (INTEGER LABELS) EXAMPLES ---")
y_true_multi_int = [0, 1, 2, 0, 1, 2, 0, 2]
y_pred_multi_int = [0, 2, 1, 0, 1, 1, 0, 2]
cm_multi_int = ClassificationMetric(y_true_multi_int, y_pred_multi_int)
print(f"average=None : {cm_multi_int.HML(average=None)}")
print(f"average='macro' : {cm_multi_int.HML(average='macro')}")
print(f"average='micro' : {cm_multi_int.HML(average='micro')}")
print(f"average='weighted' : {cm_multi_int.HML(average='weighted')}")
# Filter specific classes
print(f"Filter classes [1, 2] (average=None) : {cm_multi_int.HML(labels=[1, 2], average=None)}")
print(f"Filter classes [1, 2] (average='macro') : {cm_multi_int.HML(labels=[1, 2], average='macro')}")
print(f"Filter classes [1, 2] (average='micro') : {cm_multi_int.HML(labels=[1, 2], average='micro')}")
print(f"Filter classes [1, 2] (average='weighted'): {cm_multi_int.HML(labels=[1, 2], average='weighted')}")
# ==============================================================================
# SCENARIO 3: Multiclass Classification with Categorical/String Labels
# ==============================================================================
print("\n--- 3. MULTICLASS (CATEGORICAL/STRING LABELS) EXAMPLES ---")
y_true_str = ["cat", "ant", "cat", "cat", "ant", "bird", "bird", "bird"]
y_pred_str = ["ant", "ant", "cat", "cat", "ant", "cat", "bird", "ant"]
cm_str = ClassificationMetric(y_true_str, y_pred_str)
print(f"average=None (Class dict) : {cm_str.HML(average=None)}")
print(f"average='macro' : {cm_str.HML(average='macro')}")
print(f"average='micro' : {cm_str.HML(average='micro')}")
print(f"average='weighted' : {cm_str.HML(average='weighted')}")
# Filter string labels
print(f"Filter 'cat' & 'bird' (average=None) : {cm_str.HML(labels=['cat', 'bird'], average=None)}")
print(f"Filter 'cat' & 'bird' (average='macro') : {cm_str.HML(labels=['cat', 'bird'], average='macro')}")
print(f"Filter 'cat' & 'bird' (average='micro') : {cm_str.HML(labels=['cat', 'bird'], average='micro')}")
print(f"Filter 'cat' & 'bird' (average='weighted'): {cm_str.HML(labels=['cat', 'bird'], average='weighted')}")