GMS - Geometric Mean Score
The Geometric Mean Score (GMS) (widely known as G-Mean) [25] evaluates the balance between classification performance on the positive class (Recall/Sensitivity) and the negative class (Specificity).
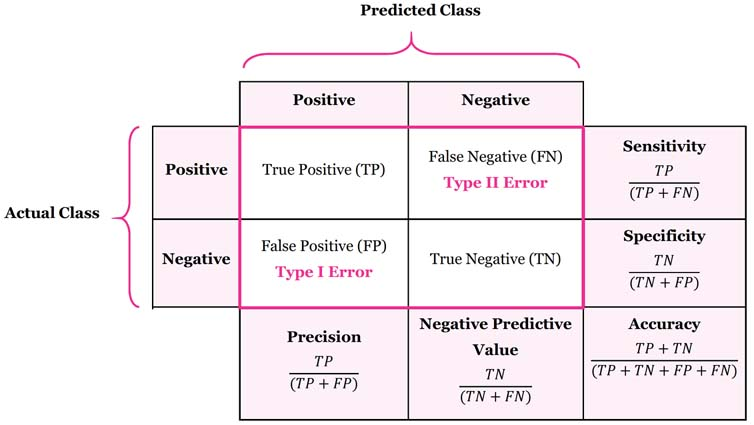
Originally proposed by [26] G-Mean is a cornerstone evaluation metric for heavily imbalanced learning. Unlike arithmetic averages that allow high accuracy on the majority class to mask poor performance on the rare minority class, the geometric mean severely penalizes extreme disparities. A classifier can only achieve a high G-Mean score if it performs strongly on both positive and negative instances simultaneously.
Engineering Insight: Geometric vs. Arithmetic Aggregation
To understand why library developers rely on the Geometric Mean for imbalanced classification, consider a dataset of 10,000 legitimate bank transactions (Class 0) and 10 fraudulent transactions (Class 1).
A lazy model simply classifies every single input as legitimate (Class 0):
* Recall (Sensitivity on Fraud): 0.0 (0 out of 10 caught)
* Specificity (TNR on Legitimate): 1.0 (10,000 out of 10,000 correctly bypassed)
If we evaluate this model using an Arithmetic Mean: .. math:
\text{Arithmetic Mean} = \frac{0.0 + 1.0}{2} = \mathbf{0.50}
The model receives a 50% score, creating an illusion of moderate utility.
However, evaluating with the Geometric Mean: .. math:
\text{G-Mean} = \sqrt{0.0 \times 1.0} = \mathbf{0.0}
The score instantly collapses to zero. Mathematically, the product inside the square root is dictated by its smallest factor. The G-Mean acts as a strict bottleneck: the model’s overall score cannot exceed the performance of its worst-performing class.
Architectural Design: Multiclass OvR Extension
While classical literature defines G-Mean strictly for binary classification, permetrics extends this metric to handle multiclass environments via One-vs-Rest (OvR) decomposition:
None: Returns a dictionary/array containing the independent binary G-Mean score for each class (treating Class \(c\) as Positive and all other classes combined as Negative).
macro: Computes the unweighted arithmetic mean of the OvR G-Mean scores across all classes. This is an exceptional benchmark for auditing models trained on skewed multiclass distributions.
micro: Calculates globally across the aggregate matrix.
weighted: Computes the mean of the OvR G-Mean scores weighted by true class support.
Properties
Best possible score:
1.0(Indicates perfect Recall and perfect Specificity).Worst possible score:
0.0(Occurs if the model completely fails on either the positive class or the negative class).Range:
[0.0, 1.0]
Example Usage
from permetrics.classification import ClassificationMetric
# ==============================================================================
# SCENARIO 1: Binary Classification
# The default 'binary' mode requires a specific positive class (pos_label)
# ==============================================================================
print("--- 1. BINARY CLASSIFICATION EXAMPLES ---")
y_true_bin = [0, 1, 0, 0, 1, 0]
y_pred_bin = [0, 1, 0, 0, 0, 1]
cm_bin = ClassificationMetric(y_true_bin, y_pred_bin)
# 1. Default configuration: average="binary", pos_label=1
gms_bin_default = cm_bin.GMS()
print(f"Default (average='binary', pos_label=1): {gms_bin_default}")
# 2. Change pos_label to 0
gms_bin_pos0 = cm_bin.GMS(average="binary", pos_label=0)
print(f"Binary with pos_label=0 : {gms_bin_pos0}")
# 3. Independent One-vs-Rest G-Mean scores per class
gms_bin_none = cm_bin.GMS(average=None)
print(f"Binary with average=None : {gms_bin_none}")
# ==============================================================================
# SCENARIO 2: Multiclass Classification with Integer Labels
# ==============================================================================
print("\n--- 2. MULTICLASS (INTEGER LABELS) EXAMPLES ---")
y_true_multi_int = [0, 1, 2, 0, 1, 2, 0, 2]
y_pred_multi_int = [0, 2, 1, 0, 1, 1, 0, 2]
cm_multi_int = ClassificationMetric(y_true_multi_int, y_pred_multi_int)
print(f"average=None : {cm_multi_int.GMS(average=None)}")
print(f"average='macro' : {cm_multi_int.GMS(average='macro')}")
print(f"average='micro' : {cm_multi_int.GMS(average='micro')}")
print(f"average='weighted' : {cm_multi_int.GMS(average='weighted')}")
# Filter specific classes
print(f"Filter classes [1, 2] (average=None) : {cm_multi_int.GMS(labels=[1, 2], average=None)}")
print(f"Filter classes [1, 2] (average='macro') : {cm_multi_int.GMS(labels=[1, 2], average='macro')}")
print(f"Filter classes [1, 2] (average='micro') : {cm_multi_int.GMS(labels=[1, 2], average='micro')}")
print(f"Filter classes [1, 2] (average='weighted'): {cm_multi_int.GMS(labels=[1, 2], average='weighted')}")
# ==============================================================================
# SCENARIO 3: Multiclass Classification with Categorical/String Labels
# ==============================================================================
print("\n--- 3. MULTICLASS (CATEGORICAL/STRING LABELS) EXAMPLES ---")
y_true_str = ["cat", "ant", "cat", "cat", "ant", "bird", "bird", "bird"]
y_pred_str = ["ant", "ant", "cat", "cat", "ant", "cat", "bird", "ant"]
cm_str = ClassificationMetric(y_true_str, y_pred_str)
print(f"average=None (Class dict) : {cm_str.GMS(average=None)}")
print(f"average='macro' : {cm_str.GMS(average='macro')}")
print(f"average='micro' : {cm_str.GMS(average='micro')}")
print(f"average='weighted' : {cm_str.GMS(average='weighted')}")