NPV - Negative Predictive Value
The Negative Predictive Value (NPV) is the exact statistical mirror image of the Precision Score. It represents the proportion of correctly predicted negative samples out of the total samples predicted as negative by the model.
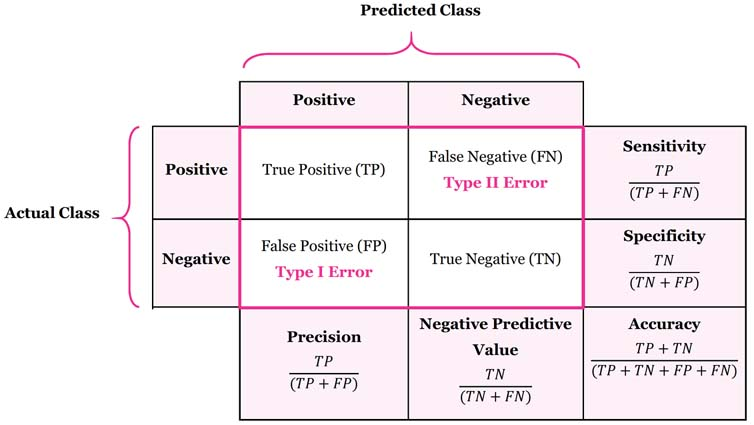
Intuitively, NPV measures the reliability of a negative prediction. It answers the vital evaluation question: “Of all the instances predicted as negative, what fraction was actually truly negative?”
Where:
\(TN\) (True Negatives) is the number of correctly predicted negative instances.
\(FN\) (False Negatives) is the number of positive instances incorrectly predicted as negative.
Averaging Strategies (Multiclass / Multilabel)
When handling more than two classes, NPV is calculated per class (treating each individual class as a One-vs-Rest problem) and then aggregated using one of the following average parameters:
None: Returns an array/dictionary of independent NPV scores for each individual class.
macro: Calculates the unweighted arithmetic mean of the NPV scores across all classes. It treats all classes equally, regardless of their support size.
micro: Calculates globally by aggregating the total true negatives and false negatives across the entire dataset: \(\frac{\sum TN}{\sum TN + \sum FN}\).
weighted: Calculates the NPV for each class and computes their average weighted by support (the number of true instances for each class).
Properties
Best possible score:
1.0(Higher value is better, mathematically indicating zero False Negatives).Worst possible score:
0.0Range:
[0.0, 1.0]Engineering Insight (Imbalanced Learning): In automated anomaly or fraud detection pipelines, NPV is critical. When 99% of transactions are legitimate (class 0), a model predicting “legitimate” must have an NPV extremely close to
1.0to guarantee that fraudulent transactions (\(FN\)) are not slipping through the automated filters undetected.
Example Usage
from permetrics.classification import ClassificationMetric
# ==============================================================================
# SCENARIO 1: Binary Classification
# The default 'binary' mode requires a specific positive class (pos_label)
# ==============================================================================
print("--- 1. BINARY CLASSIFICATION EXAMPLES ---")
y_true_bin = [0, 1, 0, 0, 1, 0]
y_pred_bin = [0, 1, 0, 0, 0, 1]
cm_bin = ClassificationMetric(y_true_bin, y_pred_bin)
# 1. Default configuration: average="binary", pos_label=1
npv_bin_default = cm_bin.NPV()
print(f"Default (average='binary', pos_label=1): {npv_bin_default}")
# 2. Change pos_label to 0 (treats 0 as the target class)
npv_bin_pos0 = cm_bin.NPV(average="binary", pos_label=0)
print(f"Binary with pos_label=0 : {npv_bin_pos0}")
# 3. When average=None, it returns independent scores for each class found
npv_bin_none = cm_bin.NPV(average=None)
print(f"Binary with average=None : {npv_bin_none}")
# ==============================================================================
# SCENARIO 2: Multiclass Classification with Integer Labels
# ==============================================================================
print("\n--- 2. MULTICLASS (INTEGER LABELS) EXAMPLES ---")
y_true_multi_int = [0, 1, 2, 0, 1, 2, 0, 2]
y_pred_multi_int = [0, 2, 1, 0, 1, 1, 0, 2]
cm_multi_int = ClassificationMetric(y_true_multi_int, y_pred_multi_int)
print(f"average=None : {cm_multi_int.NPV(average=None)}")
print(f"average='macro' : {cm_multi_int.NPV(average='macro')}")
print(f"average='micro' : {cm_multi_int.NPV(average='micro')}")
print(f"average='weighted' : {cm_multi_int.NPV(average='weighted')}")
# Using the `labels` parameter to filter specific classes
print(f"Filter classes [1, 2] (average=None) : {cm_multi_int.NPV(labels=[1, 2], average=None)}")
print(f"Filter classes [1, 2] (average='macro') : {cm_multi_int.NPV(labels=[1, 2], average='macro')}")
print(f"Filter classes [1, 2] (average='micro') : {cm_multi_int.NPV(labels=[1, 2], average='micro')}")
print(f"Filter classes [1, 2] (average='weighted'): {cm_multi_int.NPV(labels=[1, 2], average='weighted')}")
# ==============================================================================
# SCENARIO 3: Multiclass Classification with Categorical/String Labels
# ==============================================================================
print("\n--- 3. MULTICLASS (CATEGORICAL/STRING LABELS) EXAMPLES ---")
y_true_str = ["cat", "ant", "cat", "cat", "ant", "bird", "bird", "bird"]
y_pred_str = ["ant", "ant", "cat", "cat", "ant", "cat", "bird", "ant"]
cm_str = ClassificationMetric(y_true_str, y_pred_str)
print(f"average=None (Class dict) : {cm_str.NPV(average=None)}")
print(f"average='macro' : {cm_str.NPV(average='macro')}")
print(f"average='micro' : {cm_str.NPV(average='micro')}")
print(f"average='weighted' : {cm_str.NPV(average='weighted')}")
# Filter string labels: Focus calculation entirely on 'cat' and 'bird'
print(f"Filter 'cat' & 'bird' (average=None) : {cm_str.NPV(labels=['cat', 'bird'], average=None)}")
print(f"Filter 'cat' & 'bird' (average='macro') : {cm_str.NPV(labels=['cat', 'bird'], average='macro')}")
print(f"Filter 'cat' & 'bird' (average='micro') : {cm_str.NPV(labels=['cat', 'bird'], average='micro')}")
print(f"Filter 'cat' & 'bird' (average='weighted'): {cm_str.NPV(labels=['cat', 'bird'], average='weighted')}")